우선 오늘 공개된 건 일반 대화용 “GPT-5.3” 전체 라인업이 아니라, 개발자 워크플로에 최적화된 코딩 에이전트 모델인 GPT-5.3-Codex입니다. 즉 비교의 핵심은 “GPT-5.3-Codex vs GPT-5.2-Codex(그리고 GPT-5.2)”로 보는 게 가장 정확합니다.
이 글은 GPT-5.3-Codex가 GPT-5.2 대비 무엇이 좋아졌는지, 공식 지표(벤치마크)로 확인하고, 실제 개발자 커뮤니티 초반 후기를 함께 엮어 체감 포인트까지 정리해보겠습니다.
결론 요약: GPT-5.3-Codex에서 가장 크게 달라진 3가지
- 에이전트형 작업(터미널/도구 사용/컴퓨터 조작) 지표가 큰 폭으로 상승
- Codex 사용자 기준 25% 더 빠른 실행(속도 개선)
- 작업 도중 방향을 바꾸는 “실시간 스티어링(중간 지시)” UX가 안정화되고, 진행 상황 업데이트도 더 촘촘해짐
한마디로 “코드를 잘 쓰는 모델”에서 “컴퓨터 앞에 앉혀도 일 처리가 되는 모델” 쪽으로 무게중심이 더 이동했습니다. 이제 ‘코드 생성’만 잘하는 게 아니라, 리서치하고, 툴 돌리고, 테스트 굴리고, 결과 보고, 다시 수정하는 루프를 더 자연스럽게 이어가려는 방향이 명확합니다.
숫자로 보는 개선: GPT-5.3-Codex vs GPT-5.2-Codex
아래 표는 공개된 공식 벤치마크 수치 기준으로 GPT-5.3-Codex가 GPT-5.2-Codex 대비 어느 정도 올랐는지 정리한 것입니다. (점수는 높을수록 좋고, 괄호의 “상대 개선”은 단순 비율 비교로 참고용입니다.)
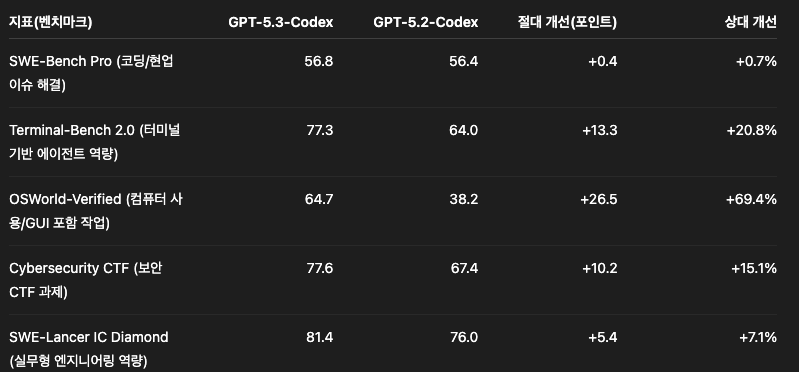
포인트는 딱 두 줄입니다.
- “순수 코드 패치 성능”을 대표하는 SWE-Bench Pro는 소폭 상승
- “에이전트형 작업”을 대표하는 Terminal-Bench 2.0, OSWorld-Verified가 크게 상승
즉, GPT-5.3-Codex는 “코드만 잘 짜는 모델”을 넘어서 “일을 끝내는 모델” 쪽으로 업그레이드 폭이 큽니다.
왜 OSWorld/Terminal-Bench 점프가 중요한가
개발자 입장에서 체감이 큰 건 보통 이런 구간입니다.
- 레포에서 문제가 재현이 안 된다 → 환경/명령어/테스트부터 정리해야 한다
- 문서 찾아야 한다 → 링크 탐색, 설정값 확인, 로그 읽기 같은 ‘부수 작업’이 더 많다
- “코드 작성”은 30%, “실행·검증·수정·다시 실행”이 70%다
Terminal-Bench 2.0과 OSWorld-Verified는 바로 이 70% 구간, 즉 “터미널을 다루며 작업을 밀어붙이는 능력”과 “컴퓨터 상에서 실제로 일을 처리하는 능력”을 더 직접적으로 겨냥합니다. 점수가 크게 뛴 건 “코드를 써주는 비서”에서 “업무를 돌리는 동료”로 가는 신호에 가깝습니다.
속도: Codex 사용자 기준 25% 빨라짐
공식 설명 기준으로 GPT-5.3-Codex는 Codex 환경에서 25% 더 빠르게 동작합니다. 이건 벤치마크처럼 “정답률”이 아니라 실제 사용 체감에 직결되는 개선입니다.
- 같은 작업을 더 빨리 끝냄
- 긴 작업(리서치→실행→검증)을 돌릴 때 대기 시간이 줄어듦
- 에이전트 루프가 길어질수록 시간 절약이 눈덩이처럼 커짐
개발자에게 25%는 아주 솔직히 말해 “점심시간이 늘어나는 수준”은 아니지만, “하루에 반복되는 답답함이 줄어드는 수준”은 됩니다.
거기다가 심지어 며칠전에 전체적인 gpt codex의 응답시간 40% 개선 작업이 있었기 때문에 체감이 더 빨라지지 않았을까 싶습니다.
UX 개선: 실시간 스티어링(중간 지시)과 더 촘촘한 진행 상황
GPT-5.3-Codex 쪽에서 강조하는 변화는 ‘성능 숫자’만이 아닙니다.
- 에이전트가 일하는 도중에도 사용자가 끼어들어 방향을 바꿀 수 있는 중간 지시(미드턴 스티어링) 지원
- 진행 상황 업데이트가 더 자주 나오고, 지시에 더 즉각 반응
이게 왜 중요하냐면, 에이전트형 코딩의 최대 스트레스가 보통 이거라서입니다.
- “어디까지 했는지 모르겠다”
- “지금 그 방향 아니라고”
- “멈추고 말 좀 들어봐”
중간 지시는 이 문제를 정면으로 해결하려는 기능입니다. 이제는 “한 번 시켜놓고 기다렸다가 결과물을 검토”만 하는 구조에서, “작업 중간에 코스 수정”이 더 자연스러워집니다.
GPT 5.3 커뮤니티 현재 반응
출시 직후 커뮤니티의 대표적인 첫 반응은 다음 톤으로 요약됩니다.
- 속도가 확실히 빠르다는 체감
- 테스트를 많이 돌리는 성향이 보인다는 후기
- 다만 첫 요청에서 버그를 만들어내기도 했는데, 바로 다음 턴에서 고치는 속도는 좋아졌다는 코멘트
또 다른 흐름으로는 “코딩 에이전트는 사람을 얼마나 루프에 묶어둘 것인가”에 대한 취향 논쟁도 있습니다. 어떤 사람은 더 자율적으로 길게 달리는 스타일을 선호하고, 어떤 사람은 중간에 계속 핸들을 잡고 싶어합니다.
GPT-5.3-Codex는 발표 톤 자체가 “인터랙티브 협업(중간 스티어링)” 쪽을 전면에 내세웁니다. 반면 커뮤니티에서는 “실제로는 오히려 더 오래 생각하고 돌아온다” 같은 상반된 체감도 함께 나오기 때문에, 본인 작업 스타일에 맞는지 짧은 태스크로 먼저 확인하는 게 안전합니다.
실전에서 이렇게 쓰면 GPT-5.3-Codex의 장점이 잘 나온다
숫자와 후기를 종합했을 때, GPT-5.3-Codex의 장점이 가장 잘 드러나는 사용 패턴은 아래 쪽입니다.
- 리팩터링 + 테스트 루프가 긴 작업
- 단순 코드 변경보다 “변경→실행→실패 로그 분석→수정” 반복이 많은 케이스
- 설정/인프라/툴링이 섞인 작업
- 예: 빌드/배포 스크립트 정리, CI 파이프라인 손보기, 환경 변수/권한 이슈 추적
- 프론트/웹 앱처럼 ‘겉모습 + 동작’이 동시에 중요한 작업
- 단순히 돌아가기만 하는 코드보다 완성도 있는 결과물을 여러 번 다듬는 작업
반대로, “짧고 단순한 함수 하나만 딱 생성” 같은 작업은 GPT-5.2-Codex 대비 체감 차이가 크지 않을 수도 있습니다. 위 표에서도 순수 코딩 지표는 소폭 상승이기 때문입니다.
마무리: GPT-5.3는 “코딩 모델 업그레이드”라기보다 “일 처리 방식 업그레이드”
정리하면, GPT-5.3-Codex는 GPT-5.2 대비
- 에이전트형 지표에서 큰 폭의 점프
- Codex 환경에서 25% 속도 개선
- 중간 스티어링과 진행 업데이트로 협업 UX 강화
이 조합으로 “코드 생성기”보다 “업무 동료”에 더 가까운 방향으로 진화했습니다.
결국 선택 기준은 단순합니다.
당신이 요즘 코딩에서 가장 많이 하는 일이 “코드 작성”인지, 아니면 “문제 재현→실행→검증→수정 루프”인지. 후자 비중이 높을수록 GPT-5.3-Codex의 업그레이드는 꽤 설득력 있게 다가올 가능성이 큽니다.
출처
- (OpenAI)
- (OpenAI Developers)
- (OpenAI)
- (Reddit)
'IT' 카테고리의 다른 글
| MS Teams DM(1:1 채팅) 관리자도 볼 수 있을까? (5) | 2026.02.23 |
|---|---|
| 카카오톡 선물하기 ChatGPT Pro 2만9천원, Plus 1+1도 2만9천원? 진짜인지, 동일한 플랜인지, 기존 사용자는 어떻게 쓰는지 총정리 (1) | 2026.02.13 |
| 2026년 2월 신형 AI모델 전쟁: GPT-5.3와 Claude Opus 4.6 정확히 비교하기 (1) | 2026.02.06 |
| OpenAI Codex macOS 앱: CLI,웹과 뭐가 다르고, 개발자 입장에서 뭐가 좋아졌는지 분석 (2) | 2026.02.04 |
| OpenAI Prism란 무엇인가?(LaTeX 논문 작성과 협업 중심) (1) | 2026.02.04 |
